
Documentation is a lot like running. But its not the satisfying, endorphin rush at the end - its the constant, exhausting struggle of putting one foot in front of the other again and again. I am 100% sure that NOBODY likes that part, and if anyone tells you otherwise, they’re lying.
Written by Cyber Defence Engineer, James Lanagan
Some might disagree about the running (sorry!), but you’d be hard pressed to find a fan of the tedious, time consuming process of writing documentation. Priorities shift quickly, and the next project is always just around the corner. As a result, documentation gets pushed down the to-do list, often leaving it outdated when the process, or strategy shifts, as it often does in an agile environment.
But documentation is undeniably important. I’ve personally experienced building products in small teams, only to find that 6–12 months later, everyone originally involved had left the company. The only way to piece the project back together is through the documentation left behind.
Documentation doesn’t just improve collaboration, it speeds up onboarding, reduces knowledge silos, and is key to ensure the long-term sustainability of work across teams.
And all this applies to detection rules, too.
Why document your detections?
Security processes are an important part of every organisation, with threat detection rules in particular forming the backbone of any SOC team. But documenting these detection rules is an often neglected benefit. A well-maintained knowledge base of detections in your environment ensures:
- Clarity of intent: While detection rule names should, where possible, state the intent of the detection itself, this is rarely enough. Threat actors use a wide variety of techniques, and detection logic can be complex, making it essential to explain in clear language what exact behaviour the rule is attempting to detect. Without this, an analyst could easily misinterpret an alert in the SOC queue and head down a wrong path when triaging, potentially wasting the analyst’s time or resulting in critical information being overlooked.
- Knowledge sharing: A centralised repository of documentation, designed to be easily updated and iterated on, allows teams to share knowledge and experience. Analysts can leave comments detailing past triage steps, patterns of false positives, and additional context that can reduce the time-to-understand when a less familiar alert shows up.
- Collaboration across teams: Other stakeholders and teams may be interested or involved in detection rulesets, such as threat intelligence analysts, operational IT, and even C-level executives, who may ask, “What is our detection coverage?” or “Would we catch this if it happened?”. A solid detection knowledge base is the first place to look when answering these questions. It can form the foundation for reporting on detections, helping track Mitre ATT&CK coverage and detection gaps.
- Auditability and compliance: As security programs mature, demonstrating that you’re proactively detecting threats becomes not just a technical requirement but a compliance and governance one. Well documented detection rules serve as evidence during audits and reviews, showing that detection logic is intentional, maintained, and aligned with threat models.
- Maintainability over time: Detection logic is not static. TTPs evolve, environments change, and detection tuning becomes necessary. Without documentation, it’s easy for rules to become “black boxes” that no one wants to touch. Documentation reduces this risk and allows future engineers to improve rather than rewrite.
This is not a new conversation. Palantir first introduced the Alerting and Detection Strategies (ADS) framework back in 2017, and it has since become a go-to for many detection engineers. While the structure may not suit every organisation’s specific needs, it provides an excellent template that can be built upon and adapted. The framework outlines several sections of documentation that must be completed before a detection is considered production ready. The more notable sections include a Detection Goal (a clear description of the activity being detected), as well as Technical Context, Blind Spots and Assumptions, False Positives, Priority, and Response. You can read more about the ADS framework and its taxonomy here.
You Will Document
Over the past six months, Dojo has moved towards a Detection-as-Code strategy. Our detection rules are now stored in a GitHub repository, and the detection and response team, known internally as the Cyber Defence Centre, collaborates daily to create new rules and refine existing ones. We’ve built a reliable CI/CD pipeline using GitHub Actions that not only performs unit tests and syntax validation, but also initiates retro-hunts against our SIEM for any newly added rules. This helps ensure that the number of firing detections stays below a defined threshold with anything above being considered too noisy.
The CI/CD pipeline even includes functionality to run end-to-end validation tests of our detection rules using Datadog’s Stratus Red Team. Under the hood this uses Terraform to spin up cloud resources, simulate attacks against them, and verify that the corresponding detections are triggered in our SIEM. The change has to beer peer reviewed by at least one team member which encourages collaboration within the team. Once a change branch is merged, all updated or new detections are automatically synced to the SIEM, providing accountability and version control.
So, what’s next? Well, as any responsible detection engineer would say: documentation!
In a move that’s slightly reminiscent of an administrative dictatorship (in a good way), we now enforce documentation through our CI/CD pipeline. For checks to pass, and for a new detection to be merged into the main branch, the author must provide documentation. No docs, no merge.
What does this look like in practice? Each custom detection rule in our SIEM has its own directory in the repo. Inside that directory, we include the YARA-L rule containing the detection logic, along with a docs.yaml file that holds the structured documentation for the rule. Where applicable, there’s also a validate.yaml file that contains the attack simulation commands used for end-to-end detection validation.

Our choice to use YAML for detection documentation was closely tied to our decision to use Notion as the centralised knowledge base for our detections and our desire to automate the process of adding new entries as much as possible. Inspiration for the structure of the Notion detection database itself came from a great article by @Rcegan.

Using the workflows configured as part of our CI/CD pipeline, we enforce several checks that must be passed before a branch can be merged. One of these checks ensures that a docs.yaml file exists for any altered rule.
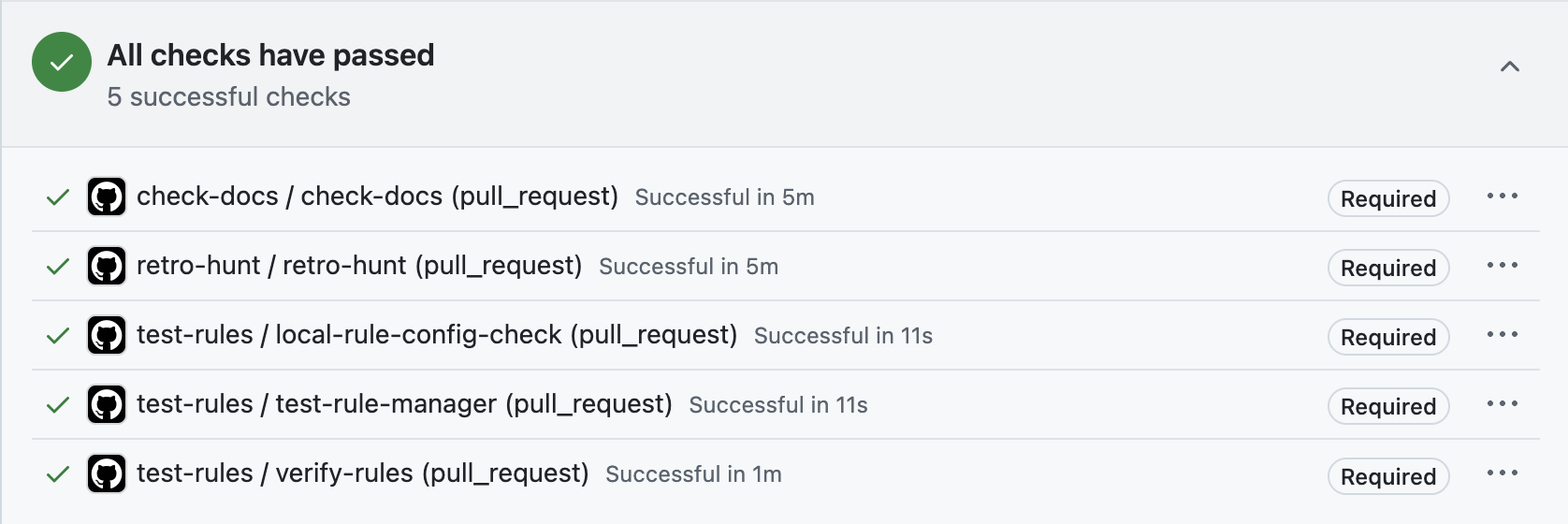
We implement the document checks with a Python script running as a step in the workflow that contains code to check if the documentation file exists for the rules being altered.

With the documentation for the rule nicely structured in YAML it is easy to read it into the Python script and pass it to a Notion API client to upload the document once the checks have passed and the merge is successful.

The Notion update scripts include logic to read the fields in the YAML file and then construct Rich Text Blocks for Notion, as shown below:


The result is a structured database that is automatically updated whenever a new detection is merged into the main branch:

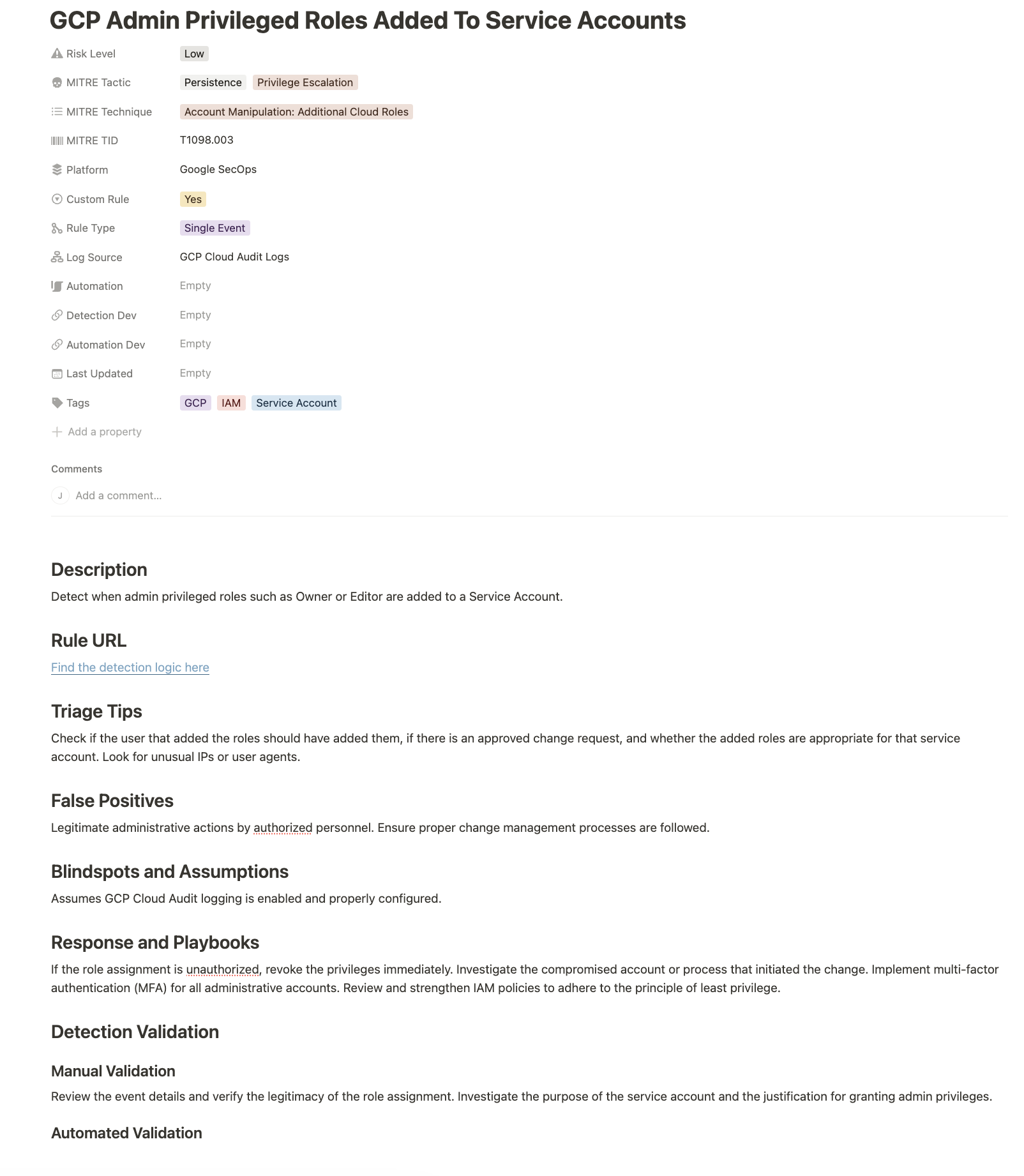
Document without Dread
We could have stopped there, right? After all, we have a fully automated detection upload process enforced by our CI/CD pipeline - all that’s left is to copy a previous YAML template and update the fields. But why not go one step further? Imagine automating the generation of documentation directly from the detection logic. With generative AI and frameworks like Streamlit and Langchain, creating internal tools and prototypes that streamline processes has never been easier.
This is where our Rule Doc Generator comes in. It provides an interface where the detection author can paste their detection logic and hit Generate to create the YAML documentation. The generated file can then be easily downloaded, adjusted if needed, and placed into the directory of the rule they’re working on.
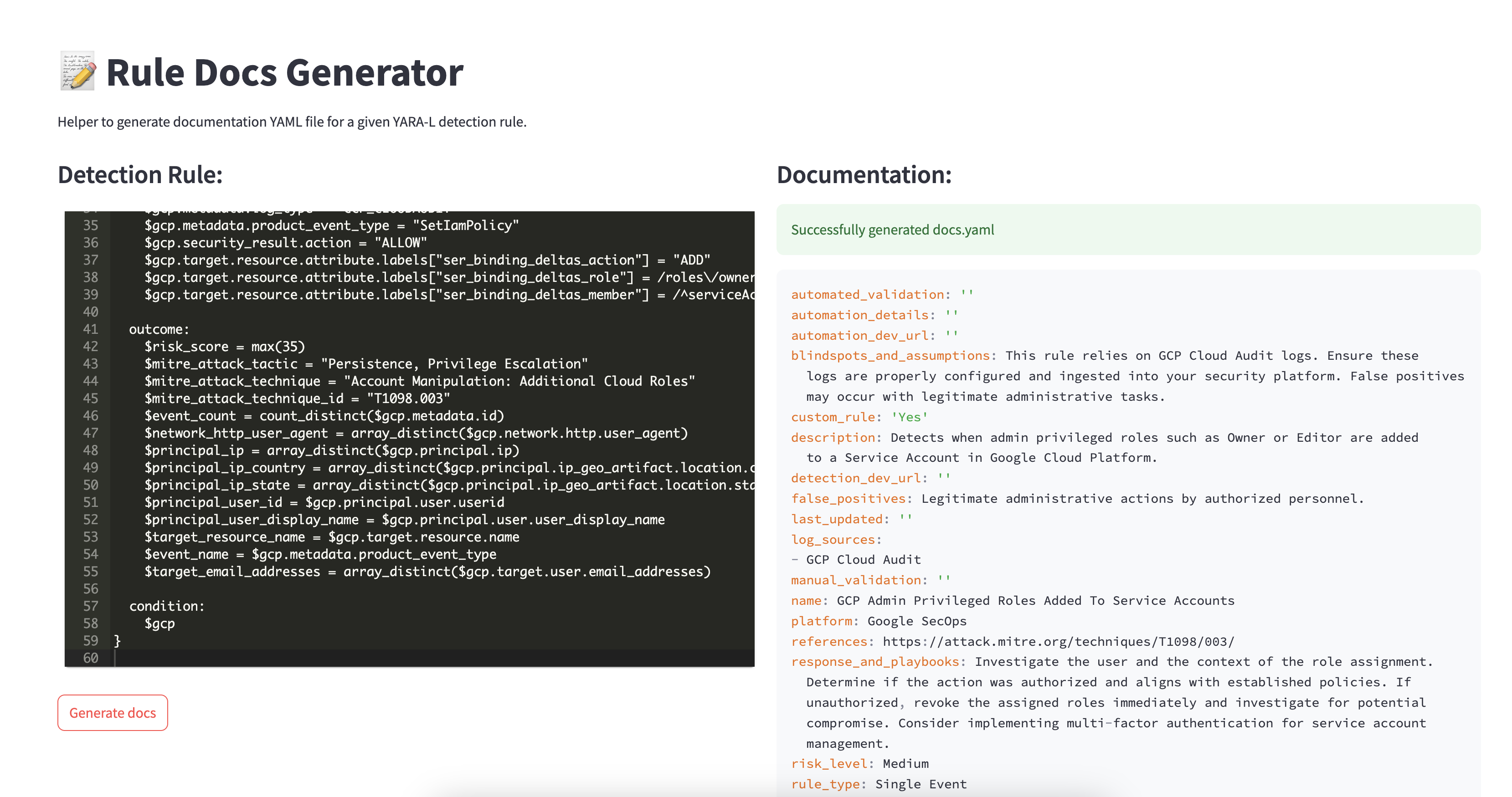


Conclusion
As we’ve seen, here at Dojo we’ve made clear progress in removing the usual headaches around documentation. With the combination of CI/CD pipelines, generative AI, and tools like Langchain and Streamlit, we’ve made the process faster, more efficient, and less of a burden. It has empowered our team to focus on refinement of documentation rather than starting from scratch. Of course, there is still work to be done, and generative AI is not a perfect solution, but we now have a great starting off point to ensure our documentation is consistent and streamlined, allowing even more time to be spend improving our detection and response capabilities.
Want to know more about Life at Dojo?
Find more information on Diversity, Equity, and Inclusion at Dojo here.